
[Event Camera] Super Resolve Intensity Images from Event camera
Updated:
이벤트 카메라로부터 얻은 데이터를 고해상도 이미지로 재생성하는 방법론에 대한 논문이다.
Title
Learning to Super Resolve Intensity Images from Events
Introduction
본 논문에서는 이벤트 카메라에서 얻은 이벤트들을 고해상도 이미지로 재생성하는 방법론에 대해 설명한다. 기존의 방법들은 이벤트들을 이미지로 변환한 후 super resolution 알고리즘을 적용하는 방법을 사용했지만, 본 논문에서는 end-to-end 방식을 제안한다.
Preliminary
Super Resolution(SR) 알고리즘은 Single Image SR(SISR), Multiple Image SR(MISR) 두 가지 카테고리로 나뉜다. SISR은 단 하나의 이미지만을 사용하는데 비해, MISR은 시간에 따른 연속된 이미지를 사용하므로 더 성능이 좋다. 본 논문에서 제안하는 방법은 연속된 이벤트 스택을 사용하므로, MISR에 더 가깝다고 볼 수 있다.
Approach
전체적은 네트워크의 구조는 Figure 2 와 같이 네 가지 영역의 연속으로 구성된다.
- Flow Network(FNet)
- Event Feature Rectification Network(EFR)
- Super Resolution Network(SRNet)
- Mixer Network(Mix)
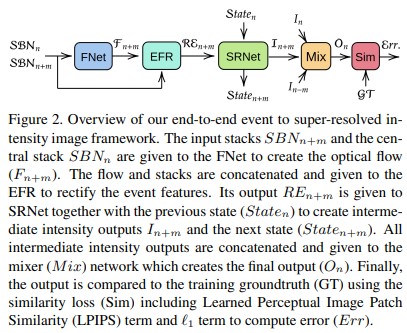
그리고 네트워크의 입력으로는 이벤트 스택을 사용하는데, Stacking Based on the Number of events(SBN) 방식으로 이벤트 스택을 만든다. SBN은 일정한 갯수만큼($N_e$) 발생한 이벤트들을 하나의 채널로 합치고, 해당 채널을 정의한 수만큼($C$) 쌓아서 하나의 스택으로 만드는 방법이다. 이렇게 생성한 연속된 이벤트 스택($h\times w\times c$)들을 네트워크의 입력으로 넣어준다. 본 논문에서는 3채널 이벤트 스택을 사용하고, 각 채널은 1000개의 이벤트를 합쳐서 만든다.
그리고 각 이벤트 스택에 대해서 마지막 APS 이미지가 GT(Ground Truth)로 사용된다.
Input
본 논문에서 제안하는 방식은 MISR과 비슷하다. 즉 일정한 갯수만큼 연속된 이벤트 스택을 네트워크의 입력으로 사용하여 하나의 고해상도 이미지를 생성하고, 네트워크 초반에 입력받는 이벤트 스택의 수 만큼 층이 나뉘어 있다. Figure 3 을 보면 직관적인 이해가 가능하다.
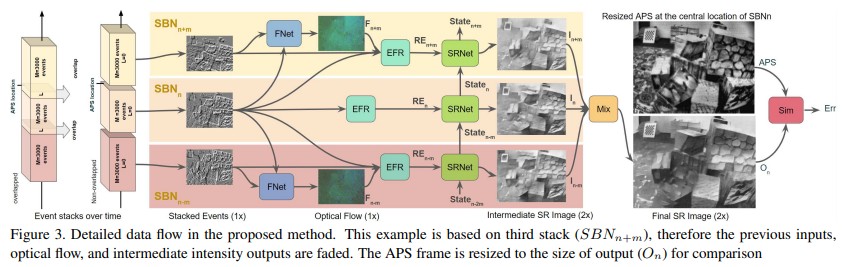
Figure 3에서 각 SBN 스택의 아랫첨자로 붙는 n, m은 이벤트에 붙는 넘버링(순서)으로 이해하면 된다. 중앙에 $SBN_n$ 스택이 들어오고, 해당 스택 전후로 m 만큼의 이벤트들이 쌓여 만들어진 SBN 스택이 존재할 것이다. 이 스택들을 각각 $SBN_{n-m},\ SBN_{n+m}$ 이라 한다.
FNet
$SBN_n$ 스택과, 전후로 존재하는 $SBN_{n-m},\ SBN_{n+m}$, 각각과 페어를 만들어 FNet의 입력으로 넣어주고, optical flow 정보를 추출한다.
EFR
FNet을 통해 얻은 결과를 다시 처음에 입력받은 스택과 합쳐 EFR의 입력으로 하여 이벤트 정보를 추출한다. 그럼 과거부터 현재, 현재, 현재부터 미래 총 세 가지의 Rectified Event 스택($RE_{n-m},\ RE_n,\ RE_{n+m}$)을 얻을 수 있다.
SRNet
이 각각의 RE들과 이전 시점에서의 state를 SRNet의 입려으로 하여 현재의 SR 이미지와 state를 출력하게 된다.
SRNet은 연속적인 정보들을 활용하기 위해 recurrent neural network 를 사용한다. 이 SRNet은 ResNet 기반으로 만들어지는데 도식화하면 Figure 4 와 같다.
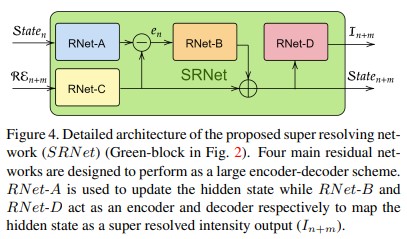
현재의 RE이 RNet-C(ResNet)의 입력으로 들어가고, 이전 state가 RNet-A의 입력으로 들어간다. 두 출력의 차가 에러텀($e_n$)이 되어 RNet-B로 들어가고 그 출력과 RNet-C의 출력을 합하여 현재 state로써 다음 시점의 SRNet으로 전달한다. 그리고 현재 state를 RNet-D에 통과시켜 현재의 이미지($I_{n+m}$)를 출력한다.
Mix
이렇게 나온 연속된 이미지들을($I_{n-m},\ I_n,\ I_{n+m}$) 하나로 합쳐 출력한 것이 결과 이미지가 된다.
Similarity Loss
생성된 이미지(O)와 GT(G) 사이의 loss function은 L1 norm과 LPIPS를 사용하여 정의한다.
$L_{sim}(O,G)=L_{l_1}(O,G)+\lambda L_{LPIPS}(O,G)$
Experiment & Result
본 논문에서 제안한 방식의 성능을 평가하기 위해 다양한 실험을 수행했다.
Image reconstruction
먼저 생성된 이미지를 down-sampling 하여 이미지 재생성에 대해서만 기존의 SOTA 급 알고리즘과 비교해봤다. (High pass filter method(HF), Manifold regularization(MR), Event to video generation(EV), Event to intensity by cGANs(EG)) GT는 APS 이미지를 사용했다. 비교 방식은 SSIM, MSE, LPIPS 세 가지 방식을 사용했다.
Super-resolved image reconstruction
이미지 재생성에서 좋은 성능을 보인 EV 방식에 SR 알고리즘을 적용하여 제안한 방식과의 비교를 수행했다.
Analysis on Loss term($L_{sim}$)
각 loss term의 영향을 알아보기 위해 $L_1$, $L_{LPIPS}$ 텀 중 하나씩 사용해보며 결과를 비교했다.
Resolution parameters
네트워크의 입력되는 스택 개수, scale 등 파라미터도 바꿔가며 실험한 결과도 확인할 수 있다.
각 실험결과는 논문에서 table과 figure를 통해 직관적인 확인이 가능하다.
Comments