
[Event Camera] Event based HDR Image and HFR Video Generation using cGAN
Updated:
이벤트 카메라로부터 얻은 정보를 cGAN의 입력으로 하여 HDR(High Dynamic Range) 이미지 혹은 HFR(High Frame Rate) 비디오를 생성하는 방법론에 대한 논문이다.
Title
Abstract
본 논문은 이벤트 카메라를 활용하여 HDR 이미지 혹은 HFR 비디오를 생성하는 방법론을 제안했다. 내가 생각하는 main contribution은 event stacking과 이를 입력으로 하는 cGAN의 활용이다. 그리고 본 논문을 읽기 위해선 이벤트 카메라란 무엇인지를 알아야 할 필요가 있다.
Event Camera
아직까진 많이 알려지지 않은 센서라고 생각한다. 해당 카메라(혹은 센서)가 기존의 카메라 센서에 비해 인지도가 낮고 많이 활용되지 못하는 이유는 무엇일까. 바로 기존의 카메라와는 전혀 다른 동작 방식 때문이라 생각한다.
이벤트 카메라는 기존의 다른 카메라 센서들과는 다르게 각각의 픽셀들이 독립적이고 비동기적으로 밝기 변화에 대응한다. 나름대로 이해한 바를 쉽게 풀어쓰자면, 움직이는 물체만 볼 수 있는 카메라이다. 즉, 기존의 카메라와는 현저하게 다른 데이터를 출력하고, 이미 사용되고 있는 다양한 vision 알고리즘을 바로 적용할 수 없다. 이러한 이유가 이벤트 카메라 활용의 장벽으로 작용하는 것 같다.
그렇다면 굳이 이벤트 카메라를 사용하려는 이유는 무엇인가. 그 이유는 다음과 같다.
- Low latency
- High temporal resolution
- High dynamic range
기존의 카메라에 비해 매우 낮은 지연을 가지고 있고, 각각의 픽셀들이 독립적으로 밝기 변화에 반응하다보니 빛(카메라 센서의 치명적인 문제점)이라는 요소에 보다 강인함을 보인다. 그렇기에 이벤트 카메라로부터 얻은 데이터를 (기존의 카메라에서 얻은 일반적인 이미지처럼) reconstruction을 수행한다면 빛의 세기에 강인한 이미지를 얻을 수 있게되는 것이고, 해당 이미지에서 기존의 vision 알고리즘을 적용한다면, 밝기 변화에 강인한 application이 가능하게 될 것이다. (이벤트 카메라에 대한 보다 자세한 설명글, 출처: Taeyoung’s Blog)
이와 같은 이벤트 카메라의 potential을 unlock하고자 한 것이 본 논문의 goal이라고 볼 수 있을 것 같다.
Introduction
이벤트 카메라는 기존 카메라에 비해 ms 단위의 low latency와 거의 $1\mu s$ 수준의 high temporal resolution 그리고 high dynamic range를 가진다. 이와 같은 이벤트 카메라의 정보를 활용한다면 기존의 카메라보다 더욱 활용도 높은 이미지를 생성할 수 있을 것이다. Figure 1에서 이벤트 카메라의 raw 데이터와 APS(Active Pixel Sensor) 프레임, 그리고 본 논문에서 제시한 방식으로 재생성한 이미지를 비교해 볼 수 있을 것이다.

해당 논문에서는 단순한 이벤트들을 SBT(Stacking Based on Time), SBE(Stacking Based on Events)와 같은 새롭게 제안하는 방식으로 stacking하여 활용하고, 최종적으로 기존의 카메라에서는 불가능했던 motion blur가 없는 HDR 이미지와 $1ms$ 수준의 FPS를 가지는 HFR 비디오를 생성할 수 있음을 보인다.
Conditional GANs
Conditional GANs(cGAN, cGANs)은 본 논문에서 메인 architecture로 사용된다. 이벤트 데이터를 활용하는데 cGANs을 사용한 것이 효율이 있음을 보인 정성적인(qualitative) 연구는 이전까지 없었다고 본 논문에서는 서술하고 있다. 동시에 cGANs은 스타일 전이(style transfer)에서 좋은 성능을 보였고, 한가지 representation에서 이미지 도메인으로의 변환에 주로 적용되었음을 논문 ref를 통해 말한다.
이벤트 카메라 데이터가 가지는 이점(low latency, high temporal resolution, high dynamic range)들을 잘 살리면서 이미지 도메인으로 변환(혹은 생성)하기 위해 cGANs을 사용한다는 것이 본 논문의 contribution 중 하나인 듯 하다.
Proposed method
cGANs은 주어진 이미지 $x$와 랜덤 노이즈 벡터 $z$를 사용하여 출력 이미지 $y$를 만들어 낸다. Generator $G$가 GT(Ground Truth)와 유사한 이미지를 만들고, 이 이미지가 실제인지 생성된 것인지 판별하는 Discriminator $D$가 존재하는 기본 개념은 동일하다.
cGANs을 활용하기 위해, 이벤트 데이터를 바로 사용 가능하도록(off-the-shelf) 하기 위한 새로운 방법론을 제안하고, 학습 네트워크에 대한 내용이 이어진다.
Event stacking: SBT vs. SBE
먼저 이벤트 카메라를 통해 얻게되는 각각의 이벤트가 어떻게 표현되는지 알아야한다. 각각의 이벤트($e$)는 네 가지 성분의 튜플로 표현된다.
$(u, v, t, p)$
$u, v: $ 픽셀 좌표
$t: $ timestamp
$p = \pm1: $ 이벤트의 극성(polarity)
이러한 이벤트 데이터들을 네트워크의 입력으로 만들기 위해 $p(u,v,t)$와 같이 3D 볼륨 형태로 stacking할 필요가 있다. 이벤트 카메라의 해상도를 $\delta t$, 이벤트를 쌓을 시간(time duration)을 $t_d$라 하고, 한 주기 동안 이벤트를 쌓는다면 그 깊이는 $n=t_d/\delta t$ 가 될 것이다. 즉 $n$채널의 이미지라고 볼 수 있다. 이러한 $n$채널 이미지는 한 주기 동안 발생한 모든 이벤트에 대한 정보를 담고 있다. 하지만 한 가지 문제점이 발생하는데, 바로 입력 이미지의 채널이 너무 커진다는 것이다.
$t_d$를 $10ms$로 설정했을 시, 이벤트 카메라의 해상도(temporal resolution)은 $1\mu s$이므로 $n=10*10^{-3}/10^{-6}=10K$, 즉, 채널이 $10K$인 이미지가 된다.
이러한 문제를 해결하기 위해, 큰 하나의 스택을 일정한 기준을 가지고 몇개의 frame으로 묶어서 한 번 더 stacking을 진행하고 한 스택의 채널(깊이, $n$)을 줄인다. 이를 수행하는 방법 두 가지가 각각 SBT, SBE이다.
SBT(Stacking Based on Time)
SBT는 말 그대로 시간 단위로 이벤트들을 하나의 프레임으로 묶는 것이다. APS의 주기를 $\Delta t$라고 할 때, 두 APS 이미지 사이의 이벤트들을 하나의 이벤트 스택으로 만들어 네트워크의 입력으로 넣어주고자 한다.
논문에서는 APS 이미지가 33FPS라고 한다. 그렇다면 한 장의 APS이미지가 출력되는 시간은 0.03초($=\Delta t=t_d$) 일 것이고, 이에 기반해 한 스택의 채널 수를 구해보면 다음과 같다.
$n=0.03/10^{-6}=30K$
무려 $30K$의 채널을 가진 이미지 스택이 된다.
SBT는 $\Delta t$의 시간동안 쌓이는 이벤트들을 $n$(앞서 사용된 스택의 깊이 $n$과는 다른 의미)개의 프레임으로 나누고, 각 프레임에 해당하는 이벤트들을 하나로 병합하여 사용한다. 그리고 이 프레임들을 묶어 하나의 스택으로써 네트워크의 입력으로 사용하는 것이다. 각 프레임에 해당하는 이벤트들을 하나로 병합하는 방법은 동일한 픽셀에 위치한 극성($p$, polarity)를 모두 더해주는 것이다.
Figure 2 를 보며 다시 정리하면 이렇다. APS 한 주기의 이벤트들을 하나의 스택으로 만들고자 하고, 한 주기는 $0.03ms$이다. 그리고 $n$(프레임의 개수)는 3으로 한다. 그렇다면 $0$~$0.01ms$ 의 이벤트들을 하나의 프레임으로 합친것이 $F_A$가 된다. 동일하게 $0.01$~$0.02ms$, $0.02$~$0.03ms$ 사이의 이벤트들을 하나로 합친 프레임이 각각 $F_B$, $F_C$가 된다. $F_A, F_B, F_C$ 세 프레임이 하나의 스택이 되는 것이고, 네트워크의 입력은 3채널 이미지가 되는 것이다.
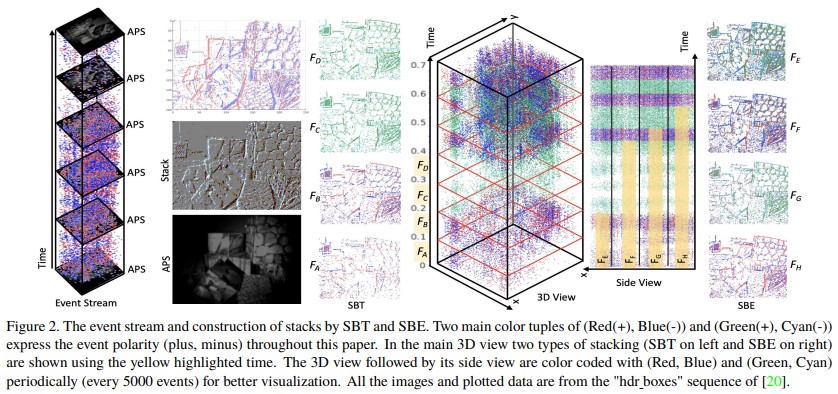
하지만 이런 방식은 매 시간 주기마다 동일한 양의 이벤트가 발생하지 않기 때문에, 어떤 스택은 HDR을 만들기에 너무 적은 정보를 가질 수 있고, 반대로 어떤 스택은 너무 과다한 정보를 가지게 된다.
SBE(Stacking Based on the number of Events)
SBT가 가진 문제를 해결하기 위해 SBE에서는 일정한 개수만큼 이벤트가 발생했을 때를 하나의 프레임으로 묶는다. 해당 방법은 모든 프레임, 그리고 프레임이 합쳐진 스택마다 동일한 개수의 이벤트를 합친 것이기 때문에 이미지를 생성하는데 일정하고 확실한 결과를 기대할 수 있다. 그리고 이벤트의 개수를 카운트할 때 시간이 흐름에 따라 카운트하기 때문에, 각 프레임, 각 스택에서 이벤트 수를 적응적으로 조절할 수 있다.
Figure 2 의 우측 그래프와 이미지가 SBE 방식으로 각 프레임을 쌓은 것이다. ($F_E$에서 $F_H$프레임의 인덱싱이 거꾸로 된 듯하다.)
Stacking for video reconstruction
위의 방법들로 생성한 스택을 사용해 이미지를 만들어냈을 때, 출력 비디오는 상당히 높을 FPS를 가질 수 있다. 아래 이미지를 보면 이해가 빠를 것이다.
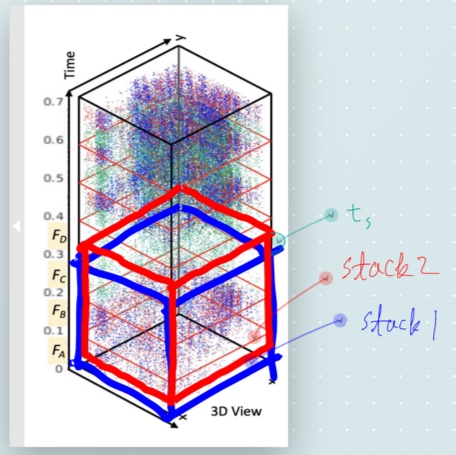
각 스택을 cGANs의 입력으로 하여 각 입력에 해당하는 이미지를 생성한다. 빨간색 스택은 파란색 스택의 첫 이벤트보다 $t_s$ 이후의 이벤트부터 쌓아올려 생성한 스택이다. 파란색 스택으로부터 이미지를 출력하고, 빨간색 이미지를 사용하여 두 번째 이미지를 출력할 것이다. 그렇다면 두 이미지가 출력되는 시간 차는 스택을 생성한 시간인 $t_s$ 만큼이 될 것이다. 이와 같은 연속이면, 결국 출력 비디오의 FPS는 $1\over t_s$가 될 것이다. 그리고 이벤트 카메라의 temporal resolution은 $1\mu s$이므로 $t_s$가 $1\mu s$라면 출력 비디오는 $1M$ FPS를 가지게 되는 것이다. 물론 $t_s$에 관해서도 정량적인 조절이 가능할 것이다.
Network architectures: cGANs
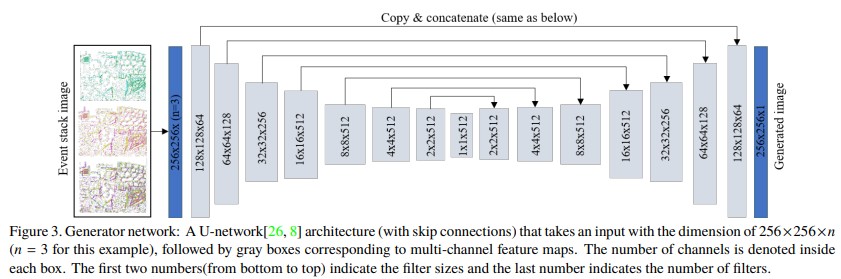
Generator
생성자는 Figure 3 과 같이 U-Net 구조에 skip-connection을 추가하여 구성한다. 그리고 입력 이미지의 경우, 앞선 Stacking 방법을 사용하여 임의의 채널 수를 가지도록 조절한다.
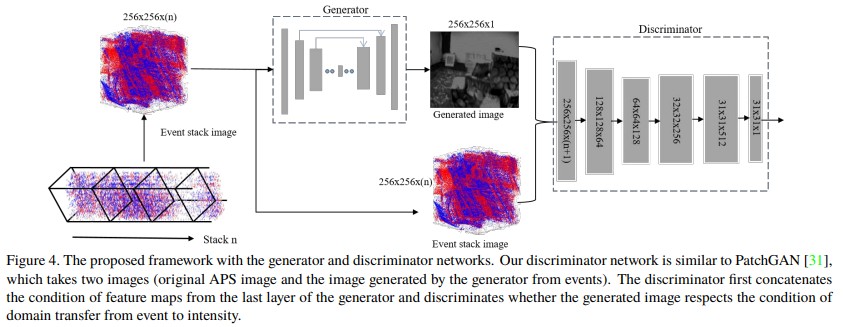
Discriminator
식별자의 경우 objective function은 다음과 같이 정의된다. 다음 식에서 $G, D$는 각각 생성자와 식별자를 의미하고, $e, g, \epsilon$은 원본 이벤트, 생성된 이미지, 그리고 generator에 추가되는 가우시안 노이즈이다.
$L_{cGAN}(G,D)=E_{e,g}[logD(e,g)]+E_{e,\epsilon}[log(1-D(e,G(e,\epsilon)))]$
그리고 blurring을 줄이기 위해 L1 norm을 사용하는데 다음과 같이 정의된다.
$L_{L1}(G)=E_{e,g,\epsilon}[||g-G(e,\epsilon)||_1]$
결과적으로 생성자는 다음과 같은 방향으로 학습을 진행하게 된다.
$G^*=arg\ \displaystyle\min_G\ \displaystyle\max_D[L_{cGAN}(G,D)+\lambda L_{L1}(G)]$
생성자와 식별자를 모두 도식화하여 전체 네트워크 구조는 다음 Figure 4와 같다.
Dataset
데이터셋은 세 가지 그룹을 준비했다.
Real-world의 이미지와 이벤트를 가지고 있는 공개 데이터셋
DAVIS 센서를 사용해 직접 제작한 데이터넷
이벤트 카메라 시뮬레이터인 ESIM을 사용해 제작한 데이터셋
이 중 ESIM 시뮬레이터를 사용한 데이터셋은 말 그대로 시뮬레이터이기 때문에 현실에서 발생하는 문제가 없기에, APS이미지를 그대로 GT로 활용할 수 있다. 하지만 현실의 데이터셋의 경우, APS에 모션 블러나 조명의 영향이 있기에 GT로 활용하기 어려운 부분이 있다.
그래서 현실 데이터셋의 경우, 흑백 영역에 해당하는 이벤트들은 제외하고 사용한다고 논문에선 서술했다. 동시에 BRISQUE 점수를 활용하거나 육안으로 확인했을 때 블러링 된 APS 이미지는 training set에서 제외하도록 했다.
Experiment & Result
현실 데이터셋을 학습하여 생성한 HDR 이미지들은 SSIM(Structure SIMilarity), FSIM(Feature SIMilarity), BRISQUE(Blind/Referenceless Image Spatial Quality Evaluator)를 사용해 평가했다고 한다.
ESIM 데이터셋을 학습한 경우 SSIM, FSIM과 PSNR(Peak Signal to Noise Ratio)를 사용해 결과를 평가했다.
SBT와 SBE를 사용하여 수행한 stacking 옵션은 아래 표와 같다.
| SBT | SBE | ||
|---|---|---|---|
| $\Delta t$ | 0.03s | # of event stack | 60K |
| # of frames($n$) | 3 |
이와 같이 학습을 수행하고 생성된 HDR의 결과는 Figure 5 와 같고, SBE에 대해서 정량적인 결과는 Table 1 과 같다.

눈으로 보기에도 SBE가 SBT보다 좋은 성능을 보이는 것을 확인할 수 있다.
Figure 6 은 ESIM 데이터셋을 활용한 것이고, SBE 방식을 사용했다. Stacking 옵션은 위 실험과 같고, 여기서는 스택의 frame 수(입력 채널, $n$)을 변형해봤다.

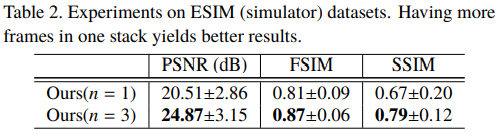
이 외에도 기존의 reconstruction 방법론과의 비교와 loss function에서 $L_1$ norm 텀을 추가했을 때와 하지 않았을 때의 결과 비교도 논문에서 확인할 수 있다.
마지막으로 본 논문에서 제시한 방법론으로 생성한 HDR 이미지와 HFR 비디오의 결과 이미지로 리뷰를 마친다.

Conclusion
cGANs을 활용하여 이벤트 카메라 데이터로부터 HDR 이미지와 상당한 FPS을 가지는 HFR 비디오를 생성할 수 있음을 확인했다. 이벤트 카메라는 intro에서 언급한 것 처럼 기존의 카메라에선 불가능했던 이점을 가지고, 이를 적극적으로 활용할 수 있다면 vision 영역에 새로운 방향성을 열 수 있지 않을까 싶다.
Comments